In my last article I talked about trying to decide on a new computer system. My current plan is to put something together after I see how much difference Bloomfield and Deneb make. Information would be nice.
People keep asking me what is wrong with Anandtech's reviews. In all honesty I would love for Anandtech's reviews to be helpful and solid because this is not an easy time to be looking for a new system. The problem is that as I go over Anandtech's information I keep coming up empty.
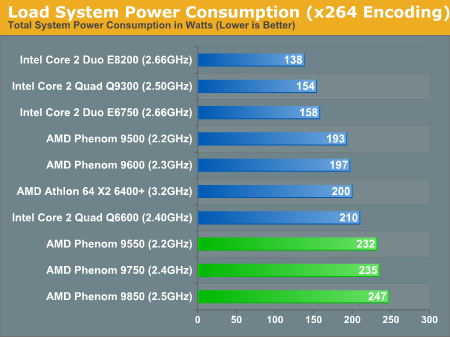
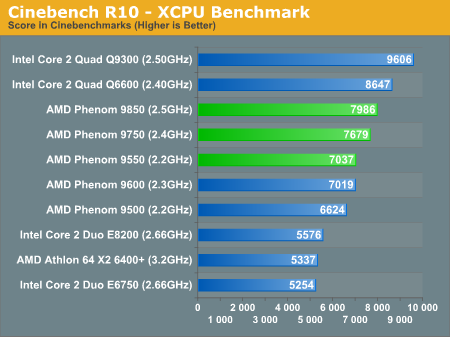
According to Anandtech's graph above, the Q9300 draws less power than the E6750. This would be quite impressive if true. However, this graph is easily falsified because according to Intel the E6750 is 65 watts whereas the Q9300 is 95 watts. So either Intel's documentation is wrong or Anandtech is. I'm pretty sure that Intel knows more about their processors than Anandtech so I'm going to have to assume the chart is wrong. And, this means that the comparison with AMD's processors is equally unreliable.
Okay, so no help on power draw. How about prices? The easiest way to see where the good prices are is to graph price versus clock. Generally the curve rises slowly and then much more steeply at some point. Anandtech seems to graph everything except these price curves. Doing my own I can see that AMD's curve is incredibly flat so there is no reason to buy anything less than a 9950 BE unless you are putting together a low end system and shopping for a dual core.
Of course dual cores and integrated graphics go hand in hand on a bargain system since you can get plenty of each for under $100. Unfortunately, Anandtech's 780G Preview isn't much help because they tossed out common sense by using the 45 watt, 2.5Ghz 4850E instead of the perfectly acceptable 65 watt, 2.7Ghz 5200+ which is the same price. However, a far better value would be spending $10 more and getting the 65 watt, 2.8Ghz 5400+ Black Edition with unlocked multiplier. Also, they didn't bother doing any real testing, just video playback, so the article is nearly worthless. Well, how about the IGP Power Consumption article? No, this article is particularly daft because it should already be obvious to everyone that integrated graphics consume less power than discrete video cards. Secondly, the article has no performance information so it is impossible to determine any value. So, how about the NVIDIA 780a: Integrated Graphics article? This article is also lacking because they use a 125 watt 9850 quad core. This is really bizarre considering their earlier insistence on a 45 watt chip. Wouldn't common 65/95 watt chips make more sense? They also leave out any comparison with Intel systems. This is quite odd since the inclusion of nVidia should have allowed a cross comparison by normalizing based on nVidia/AMD with nVidia/Intel. So, this is no help in choosing between an AMD and Intel system. Finally, the Intel G45 and AMD 790GX articles are only token announcements with no actual testing. Clearly if we are looking for a low end system Anandtech is no help at all.
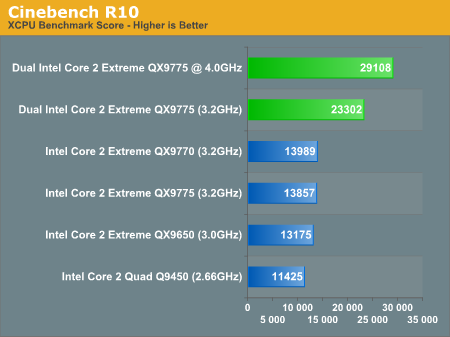
But since I'm not looking for a bargain system I'm really more interested in quads. Even though it is obvious that the 9950BE is the best value in AMD quads the value of the 750 southbridge can't be determined by a price graph. Anandtech does have a 750SB article which does show increased overclocking as well as an increase in northbridge clock but since they fail to do any actual testing you have no idea what value this might be. If we wanted to find out about Intel overclocking then there is more information. Well, sort of. In Anandtech's Overclocking Intel's New 45nm QX9650: article he does overclock all the way up to 4.4Ghz. However, curiously missing are power draw and temperature graphs. In fact, besides synthetics there is almost nothing in the article. The article itself even admits this:
We hope to expand future testing to include real-world gaming results from some of the newest titles like Crysis, Call of Duty 4: Modern Warfare, Unreal Tournament 3, and Gears of War. Stay on the lookout for these results and others in our next look at the QX9650 when we pair this capable processor with the best motherboards companies like ASUS, Gigabyte, MSI, abit, DFI and Foxconn have to offer.
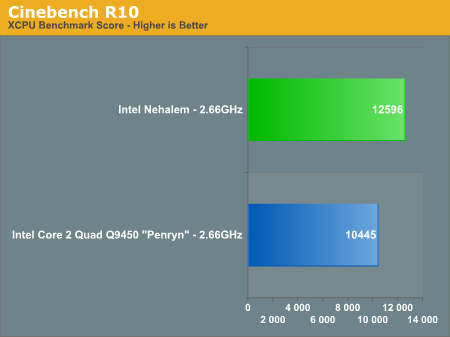
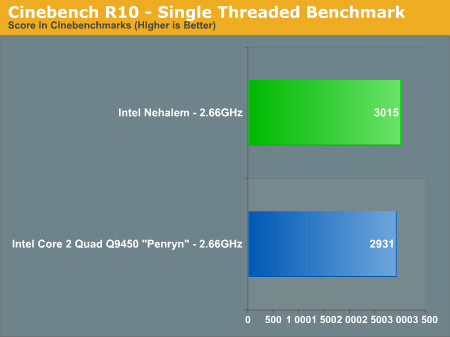
The problem is that this article is from December 19, 2007 and eight months later there is still no followup article. Anandtech does however have articles on Atom, Larrabee, and Nehalem which also have little value in choosing a system today. However, Anandtech's Nehalem article is quite odd because it says:
We've been told to expect a 20 - 30% overall advantage over Penryn and it looks like Intel is on track to delivering just that in Q4. At 2.66GHz, Nehalem is already faster than the fastest 3.2GHz Penryns on the market today.
If this is true then Intel hasn't just shot itself in the foot; it has taken a chainsaw to both legs. This would mean that the value of Intel's entire 45nm quad line has just dropped through the floor and the effect on the 65nm line would be even worse. Considering that today Intel is only at 1/3rd 45nm production by volume this would mean that Intel would have massively reduced the value of most of its line. And, if this is true then no one should buy anything higher than Q6600 until Bloomfield is released. The problem with this scenario is that Intel already went down this road with PII and PII Celeron so I doubt it will make this mistake again.
Graphics are also a bit strange at Anandtech. For example, in the HD 4870 article Anand says:
For now, the Radeon HD 4870 and 4850 are both solid values and cards we would absolutely recommend to readers looking for hardware at the $200 and $300 price points. The fact of the matter is that by NVIDIA's standards, the 4870 should be priced at $400 and the 4850 should be around $250. You can either look at it as AMD giving you a bargain or NVIDIA charging too much, either way it's healthy competition in the graphics industry once again (after far too long of a hiatus).
So, he likes the HD 4870. And, in the NVIDIA GeForce GTX 280 & 260 article he said:
the GeForce GTX 280 is simply overpriced for the performance it delivers. It is NVIDIA's fastest single-card, single-GPU solution, but for $150 less than a GTX 280 you get a faster graphics card with NVIDIA's own GeForce 9800 GX2. The obvious downside to the GX2 over the GTX 280 is that it is a multi-GPU card and there are going to be some situations where it doesn't scale well, but overall it is a far better buy than the GTX 280.
Keep in mind that the 9800 GX2 is dual GPU and cost $500 at the time of the article. The tone changes however in the Radeon HD 4870 X2 article. Anand admits:
The Radeon HD 4870 X2 is good, it continues to be the world's fastest single card solution
He also says:
But until we have shared framebuffers and real cooperation on rendering frames from a multi-GPU solution we just aren't going to see the kind of robust, consistent results most people will expect when spending over $550+ on graphics hardware.
So, he doesn't have a problem endorsing a $500, dual GPU card from nVidia yet he balks at endorsing a $550, dual GPU card from AMD that is much more powerful. This does seem more than a little arbitrary.
I might be interested in Linux but Anandtech hasn't done a Linux review since 2005. It is possible that they lost all of their Linux expertise when Kristopher Kubicki left. That's too bad but with a quad core I am very interested in mixed performance but Anandtech likewise has not done mixed testing since 2005 even under Windows. Yet, this is what the processor would typically be doing for me, running two or three different applications. Under normal circumstances I wouldn't be running four copies of the same code nor would I be splitting up one application among four cores but this is the only type of testing Anandtech does these days. This leaves a huge gap between the typical Anandtech testing which is only suitable for single and to some extent dual cores and the all out quad socket/quad core server benchmarks that they ran.
The bottom line is that Anandtech's testing is only dual core caliber (when it is accurate). However, the poor integrated graphics testing offers no help for a typical system that would be used with dual core. But even in the area of quad core/discrete graphics where Anandtech should be strong you have to deal with their schizophrenic attitude about multi-card/dual card graphics and their ambivalent attitude about power consumption. Pricing seems to get similar ill treatment at Anandtech mostly as a crutch when it happens to support their already drawn conclusions. So, my conlusion would have to be that Anandtech isn't much help in choosing a computer system.