AMD K10 Tries To Grow Some Teeth
It has been a long, long wait for proper testing on K10. The previous hasty reviews generally showed K10 doing poorly with user applications and pretty well with server applications. Unfortunately, there never seemed to be enough information to determine if K10 were working properly or contained some serious design flaw. With the update review at Legit Reviews we now have at least some information.
It is clear that the initial teething problems with ATI have been taken care of. The new Spider platform looks to be first rate and a good win for AMD. However, this platform does need a good processor and AMD has been slow to respond. The Phenom is apparently shipping but only as 9500 (2.2Ghz) and 9600 (2.3Ghz). Things don't really get interesting until 9900 (2.6Ghz) but this is either not available until Q1 or may even be pushed back to Q2 as recently stated by Digitimes. Of course, the same source also says that Intel is delaying the Core 2 Quad Q9300, Q9450 and Q9550 until late Q1. The difference is that AMD has not commented while Intel has confirmed the delay. However, Charlie at The Inquirer says that Intel is still have teething problems of its own with its 45nm process. I have to say that this again brings up the question of how much FUD is in factory previews. We have Intel showing Penryns clocked to 3.33Ghz and AMD showing K10's clocked to 3.0Ghz with neither chip anywhere on the horizon. I guess in this smoke and mirrors contest Intel does seem to be closer to reality with a 3.2Ghz Penryn QX9770 scheduled maybe end of Q1 while AMD hasn't yet indicated when 2.6Ghz will be out. And, of course, with Intel's current lead the question of a delay in 45nm is moot unless AMD is planning to essentially skip 65nm versions and start producing 45nm in Q2 (delivery in Q3). That is about the only way I could see AMD getting back on track.
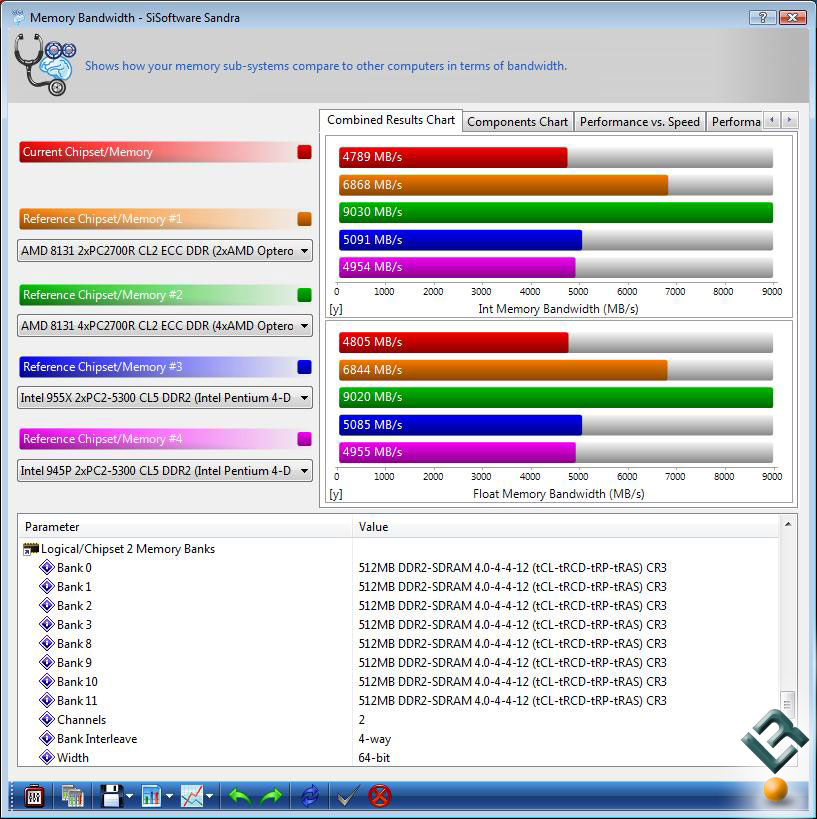
Okay, back to our original point. Assuming AMD manages to get real hardware out the door someday and make the 9900 more substantial than vaporware what do we have to look forward to? Is 9900 a contender or joke? This was the original Sandra XII scores showing very poor performance for K10 in both Integer and FP (the red bar). Such poor performance suggested a serious problem with K10. However, the new Sandra XII SP1 scores show double the previous scores removing any question of a serious design error in the memory section. The Sandra XII SP1 score of 10306 is fully 52% greater than Intel's QX9770. This explains why K10 does so well on memory limited benchmarks. Even more importantly however is the fact that it is 13% faster than 6400+ showing that K10's hardware changes to the memory controller do make a difference.
Next we need to revisit the two benchmark rumors that dogged K10 long before its release: Pov-Ray and Cinnebench. Early scores from these two benchmarks had Intel enthusiasts cackling and howling that K10 was no faster than K8. Neither was a proper benchmark but this didn't seem to stop the naysayers. We can see on the PovRay scores that 6400+ has to be 20% faster to get 2% better peformance than E6750. Thus C2D is about 18% faster than K8. However, in answer to the notion that Pov-Ray proves that K10 is no faster than K8 we see that there is no such proof. If we take the E6750 score and scale it to quad core at 2.4Ghz we can see that Q6600 scales 98% which is a very good score. However, K10 scales 102%. This suggest that K10 is at least 4% faster than K8. Since Q6600 shows no bandwidth limitations we know that the improvement is not due to memory. True, the change is small but for unoptimized code it is significant. The PovRay website also does not say what level of SSE is supported in the 64 bit version. Judging from the small increase from K8 to K10 and C2D it is clear that PovRay is not using 128 bit SSE operations. It does say that the 32 bit version only supports up to SSE2. It also does not say what compiler was used to create the executable. This too is significant since if Intel's compiler were used, K10 would take at least a 10% hit in speed. This could easily put K10 even or perhaps slightly ahead. Again, in terms of K10's speed relative to K8, the Pov-Ray Realtime scores are even more telling. Intel does manage perfect scaling with QX9770 versus E6750. However, K10 is fully 11% faster than 6400+ would be with perfect scaling. So, the Pov-Ray rumor is shelved.
Next we examine the contraversial Cinnebench scores. At the bottom we can see that K8 needs 20% more clock speed to run neck and neck with E6750. With this benchmark we see a problem though. K10 only scales 88% of 6400+. This isn't far off of Q6600's 90% scaling. However, when we look at the Penryn's we see something different. The 3.0 and 3.2Ghz Penryn's show perfect scaling from E6750. We know that this is not due to code tuning since Q6600 is slower. We know that it is not due to memory bandwidth since 9900 is slower. This pretty much only leaves cache size as the determining factor. Unfortunately, a benchmark that fits into Penryn's larger cache to run full speed is worthless for performance comparison. So, Cinnebench is still up in the air. However, given the improvements that we saw with Pov-Ray I think the Cinnebench scores can be ignored for now. When Shanghai is eventually released it will have a good deal more L3 cache than K10. If its Cinnebench scores perk up then we will know for certain that Cinnebench is useless due to cache tuning.
I could go over the rest of the benchmarks in the review but for the most part they are useless since they do not utilize all the cores. And, if we aren't using all the cores then why not just buy a dual core system? We can see that there are still questions of how benchmarks are compiled and that Intel may still be getting an edge due to the use of its compiler which is still heavily tilted in its favor. We can see that a lot of software still has not caught up to the use of 128 bit SSE codes which is the only way that C2D or K10 show their SSE strength. Older processors as far back as PIII work quite well with 64 bit SSE as does K8. And, there still remains the problem of multi-threading since a quad core is useless without quad threads. Nevertheless, this has answered a couple of questions. There is no big design defect in the K10 memory controller as earlier benchmarks suggested and K10 is clearly faster than K8 in terms of Pov-Ray. Unfortuately, we still have not turned up any real proof of whether K10's 128 bit SSE functions are on par with C2D's (and roughly twice as fast as K8's). Hopefully, this information will turn up eventually.
For now, all we can say is that assuming K10 is a signficant improvement on K8 AMD needs to get it out the door at speeds of 2.6 Ghz and above and sooner rather than later. For AMD's sake we also have to wonder if 45nm is truly still on track which should mean skipping some 65nm parts or whether this has slid as well. I suppose nothing but time will tell. Worst case for AMD would be Intel with 3.2Ghz and 3.33Ghz desktop Penryns and Nehalem launched to tackle the server market while AMD struggles to reach 2.8Ghz on 65nm with 45nm pushed back to 2009. Best case would probably be starting production of 45nm Shanghai parts in Q2 with delivery in Q3 with parts available in clock speeds of at least 3.0Ghz while still fitting within the normal TDP and Intel still at 3.2Ghz with Penryn. The sad part for AMD is that I could see either of these scenarios happening and neither one is particularly bad for Intel. We all know what AMD's New Year's resolution should be; we just don't know if AMD is capable of living up to it. C2D has some serious teeth and the fangs are just getting longer with Penryn; K10 with milk teeth is far less threatening.
{kind=link}
{kind=link}
95 comments:
What is wrong with having a
Quad Core if some of your apps are only utilizing say one or two cores and some are utilizing all four cores?
You don't want to talk about the other apps why? they are still an indication of IPC, just not scaling.
Some of my apps use all 4 cores, some use only 2 and some are not multi-threaded at all....so why would I buy a dual core over a quad core?
Why not get best of all worlds?
Some of the benchmarks they did used all 4 cores, some used 2 and some used 1....welcome to the REAL WORLD?
Did you buy a dual core to ONLY run multi-threaded apps?
Your comment makes NO SENSE.
Mo, if you own a QuadCore system but only use quad threaded software sometimes and stick mostly with single/dual threaded mix, then you have greatly overpaid for your system.
If you can't even manage 'your needs vs. your finances' ratio then why should we trust your opinion about quad threaded apps?
For a Server-CPU its ok to clock at 2,6 GHz, in the Desktop-Area AMD needs 3+ GHz to fight back not only with their low prices.
Hi,
First time reaction from me:
Scientia what do you think about this: (assuming it's true)
http://www.dailytech.com/article.aspx?newsid=9995
first sample in January and production still in the first half of 2008 while they say it normally takes 11months.
Do you think it is possible if they only have the first bootable sample in Januari?
And they say the bug isn't a problem in 45nm how can that be.
isn't it the same design that also needs a fix?
Thanks
So according to you azmount, unless I run 100% 4-threaded apps, I shouldn't get a quadcore?
Even though half of what I do on the computer is video/audio encoding/ripping which uses all 4 cores....
SO why would I not spend the $200 (what I paid, fry's deal) on a quadcore and get the most out of my system?
I still don't understand your logic?
It's just as bad as you calling a review biased communism when they use faster ram for intel and then you calling a review fair when they use faster ram on AMD.
I'm so sick of AMD trolls like azmount.
Mo you just showed us what many spIntel fans do so often, so a lot. First you said this:
Some of my apps use all 4 cores, some use only 2 and some are not multi-threaded at all....
Then you extravagated your 'use' of multithreaded applications in to:
half of what I do on the computer is video/audio encoding/ripping which uses all 4 cores....
Not that those are completely different things, but the way you served them suggest that what you want isn't to argue but to force people in to thinking your way.
azmount
Okay, I fixed the typo. C2D is 18% faster than K8.
mo
If you use four threads half the time then I would say that you need quad core. However, most people who get an Intel quad are only going to be getting a Q6600. Very few people will be buying 3.0Ghz models to get quad core and top single thread performance.
sharikouisalwaysright
2.6 Ghz would at least cover the mainstream. Right now, AMD has nothing faster than 2.3 Ghz. However, with 3.2 Ghz Penryns coming I would say 2.8 Ghz would be needed to cover most of the middle.
kedas
I can't honestly say about the timeframe from Shanghai first silicon to production. I'm sure that Brisbane was much faster than 11 months but it wasn't much of a change. A better comparison might be Revision G but I haven't found an announcement of when this taped out. If first silicon is January for Shanghai then tapeout could have been October. 11 months from then would be September 2008. I'm thinking August would probably be the earliest so September seems possible.
I suppose it is possible Shanghai doesn't include the TLB bug. That would depend on whether or not Shanghai had different masks for that section. It's possible; I just don't know how likely it is.
even a 30% use of apps that use all four cores is justification of a quad-core purchase in my eyes.
If you can save time on 30% of your apps, you wouldn't?
Give me a break.
Hey Azmount, where are your 3.6ghz brisbanes on air cooling?
Someone should really point out the having 4 threads in a single application is far from being enough to utilize a quad core CPU.
Writing software that scales linearly on >=4 cores is a very complicated task - far above and beyond what most C#/JAVA/VB#/etc programmers are capable of.
- Gilboa
gilboa said...
Writing software that scales linearly on >=4 cores is a very complicated task - far above and beyond what most C#/JAVA/VB#/etc programmers are capable of.
I see.
Well, I'll be telling my boss on Monday that what he has us doing, is to complicated and that we will spend few extra weeks reworking things back to single threaded concept.
I see.
Well, I'll be telling my boss on Monday that what he has us doing, is to complicated and that we will spend few extra weeks reworking things back to single threaded concept.
Even though you're just flame baiting, I'll bite:
What type of application are you developing?
- Gilboa
Actually Gilboa my post was purely humorous (o thou not without a grain of truth).
I work with hardware.
gilboa
I'll have to agree. Typically you only split the most cpu intensive section into multiple threads (assuming that the data structures cooperate). Sometimes these sections are not the bulk of the total application cpu demand.
Some of it is a limitation of the code structure. For example, you can distribute a sort like Merge Sort or Quick Sort fairly easily but trying to distribute Heap Sort is much harder because of the tree structure.
Distribution seems to work pretty well for things like database searches, brute force searches, statistical and counting operations, and on a lot of bulk data manipulations and conversions. These are not typically associated with common desktop applications.
Also, some of these work much better with multiple processors so that you can distribute data as well. With multiple cores on one chip it has to be an operation that can fit into cache without taxing the memory bandwidth.
Portland Group claims to have some automatic threading functions in the latest version but I don't know how useful they are.
IMHO Most of the Q6600 buyers will never utilize more then two cores (unless they participate in computation intensive projects such as BOINC/S@H/F@H.
Unlike server applications (which are easily broken into multiple threads) desktop usage-case tend to be composed by either:
A. Office application.
B. Client application.
C. Content creation.
D. Computer games.
A and B tend to be fairly linear and usually user-bound and not CPU bound.
C is a good candidate for multi-threading (especially tasks such as rendering and image special effects - both of which can easily broken into threads by alternate rending and/or break a single images to multiple smaller ones)
D is the main problem. Games tend to be very synchronization sensitive - making them far more serialized then any other desktop task. (E.g. frame -> sound sync; Player -> server sync; etc.) Far worse, most of the graphics libraries are either serialized to death (<=DX9), immature (DX10) or are suffering from problematic drivers. (OpenGL)
In short, beyond OpenGL workstation applications, I've yet to see a single game that scales linearly to two cores. (Let alone on four)
In the end, if writing MT applications that scale linearly was easy, good
programmers would have been earning 40K$ a year instead of ~150K$...
- Gilboa
Scientia,
Take a look here:
AMD Phenom Review-Update
New Years Prediction:
1) AMD will suck losses thru the first half of the year and only break even as AMD changes business models during the 2nd half of the year.
2) Ruiz will get terminated in the 2nd half of 2008 due to continued execution problems as AMD changes direction.
3) AMD 45nm CPU volume will be late materilizing in Q4 a full 2 quarters later then promised
4) Nehalem will underwhelm but Penrym on 45nm will keep INTEL ahead.
5) AMD will exit Q4 known more for its graphics processors then CPU leadership.
lex
"1) AMD will suck losses thru the first half of the year and only break even as AMD changes business models during the 2nd half of the year."
I would say you are half right. I would also expect AMD to lose money in Q1 and Q2 however I doubt there will be any big change in business model in the 2nd half.
"2) Ruiz will get terminated in the 2nd half of 2008 due to continued execution problems as AMD changes direction."
Hmmm. This one is vaguely possible. Ruiz is planning to retire and we already know who his replacement is. I would say 2009 would be more likely though.
"3) AMD 45nm CPU volume will be late materilizing in Q4 a full 2 quarters later then promised"
Actually this would be one quarter late, not two. Production of 45nm is supposed to start in Q2 with delivery in Q3. Q4 would be one quarter late. This is possible.
"4) Nehalem will underwhelm but Penrym on 45nm will keep INTEL ahead."
This is possible too.
"5) AMD will exit Q4 known more for its graphics processors then CPU leadership."
I'm not sure what year you are referring to. However, your statement is delusional. Processors are the bulk of AMD's business and this is not likely to change in 2008.
You have a number of errors but overall this is better than your usual predictions.
I can't really make too many predictions of my own. It isn't clear yet if AMD's 45nm program is really on track or this is just more PR. It isn't clear if K10 is working properly. It isn't clear if 65nm will scale. It isn't clear if 45nm will scale. It isn't clear yet if Shanghai is significantly better than Barcelona. Nehalem is still pretty much an unknown. Too many unknowns.
Scientia:
I noticed a while ago you were talking about how the Caneland platform will only have a one year lifespan, this is incorrect.
Before Beckton (native octa core, 45nm processor based on Nehalem) comes to market in 2009, Intel will launch Dunnington in 2008.
Dunnington is a 45nm native hex-core CPU based on the Core architecture that fits into the same Clarksboro chipset as Tigerton. It features 2MB shared L2 cache per pair of CPU cores, and a large shared L3 cache (I don't remember the exact size - but I believe that it's either 24MB or 16MB in size).
In 2008 only the high end desktop with Bloomfield, and the DP server market with Gainestown will see Nehalem products launch.
I just noticed a small error in my own post. Dunnington has 3MB of shared L2 (like the lower end 45nm Core 2 Duo CPUs will) per pair of cores, not 2MB.
Dunnington is supposed to be a 6 core chip. (Hex-core == 16 cores.)
... Though as far as I know, the 3x2 core configuration has yet to be confirmed.
- Gilboa
randy
True, if Intel does not release a 4-way Nehalem in Q4 2008 then Caneland would be around more than 1 year. However, how much more lifespan are we talking about? Is 4-way Nehalem due in, say, Q1 2009?
Dunnington is supposed to be a 6 core chip. (Hex-core == 16 cores.)
You're correct. That's another error I made(oops!). Hexa-core, not hex-core. :)
True, if Intel does not release a 4-way Nehalem in Q4 2008 then Caneland would be around more than 1 year. However, how much more lifespan are we talking about? Is 4-way Nehalem due in, say, Q1 2009?
I've heard that Dunnington will ship before Nehalem this year, so we're probably looking at a Q3 introduction. As for Beckton, I'm not really sure. It's supposed to be in 2H09, but that's a pretty wide timeframe. To my knowledge, Beckton hasn't taped out yet.
There's also the chance that Intel will have problems with Beckton, being such a complex processor. Putting eight cores on a single die, with more cache than two Nehalem quad core CPUs is no small task. Though, it seems fairly likely that Intel will have a quad core version of Nehalem for MP servers as well.
Why did AMD fail to implement High K for .45 nm node ?
Why did AMD fail to implement High K for .45 nm node ?
Because IBM's 45nm high-k process is simply not ready yet.
You won't see high-k metal gate from IBM or AMD until 32nm.
giant is about half right. IBM has talked about implementing high K later in 2008. They didn't say what they might use it on so it may not be for a Power cpu. However, AMD has specifically said that they may or may not implement high K before 32nm but not before mid 2009 at the earliest. If Bulldozer is truly off the map and Shanghai will be hanging around all through 2009 this does seem to make the use of high K more likely assuming the process is ready by then.
Bulldozer confirmed as coming in 2010 now:
The Sandtiger processor--based on the Bulldozer cores--will now have to wait until 2010, an AMD representative confirmed. The representative declined to elaborate on who was responsible for that decision, but noted that this time around, the company's customers approve of the decision to minimize risk.
http://www.news.com/Dirk-Meyer%2C-the-man-to-watch-at-AMD---page-3/2100-1006_3-6224419-3.html?tag=st.num
This means that AMD will have to combat Nehalem and the 32nm shrink, Westmere, with Shanghai.
giant
"This means that AMD will have to combat Nehalem and the 32nm shrink, Westmere, with Shanghai."
Not exactly. AMD should also be ready for a 32nm shrink soon after Intel.
IBM HighK will be late. They make lots of noise about having gate first but to date have shown nothing. If they had anything they would for sure be shouting from the roof tops and publishing at the conferences. It was notable at IEDM they said nothing. For IBM to not be there boasting says it all
It is also certain that consortiums have the benifit of pooling money but then need to deal with compromise between all of them on mundane things like do you optimize Design rules for transistors, contacts, metal and vias for high performance, power, or density. Sorry last time I checked each company in the consortium is looking at using their 45nm and 32nm portfolio for a vastly different application and need something different.
In the end the 45nm and 32nm process that comes out is a COMPROMISE for all. For those like Toshiba, SONY, SMIC and others that compromise is okay as they don't directly compete against anyone else at that node. AMD its another matter, they compete against INTEL with a huge and deep R&D budget, no compromise approach to producing a process optimized for power/performance of leading edge CPU.
So you got AMD coming late with an inferior process. BEing late in this business means you reap little of the benifit of the shrink as you are late with yield learning, performance while INTEL will have worked all that out. Lastly even when AMD makes it to 45nm it will be an inferior process by a good 20-30% in IBM and AMD's own words. Pretty big handicap. Shanghai and anything else AMD has to offer over the next two years will not be competitive if INTEL continues to execute.
This blogger will say I'm speculating, but those that are close to process and or CPU design know the truth.. others are ignorant bystanders and they can continue to blog all they want but can't change the fact. If you think AMD stock is cheap wait another quarter. I'm sure them Arabs have a toough time swallowing what fools they were made on their initial investment
AMD will be fodder for takeover and private equity soon. I expect them to be below 6 bucks pretty soon and then 5 bucks after which a change in business model will happen.
THere is also a good read on why DIrk is the wrong person at the wrong time to be running AMD.
AMD is finished
Not exactly. AMD should also be ready for a 32nm shrink soon after Intel.
Wasn't Bulldozer supposed to be a 45nm product, with a 32nm shrink coming aftewards?
Do you think that they will shrink K10 to 32nm in the meantime? If they did, it would be odd for AMD to have a 32nm K10 and then to introduce a 45nm Bulldozer.
Unless, that is, Bulldozer has been pushed out to 32nm.
LOL :)
I had to laugh at Lex's crap.
He's always good at writing crap. Keep on the good work man. lol
Lex wrote:
Lastly even when AMD makes it to 45nm it will be an inferior process by a good 20-30% in IBM and AMD's own words.
LOL, an inferior process. =)
I guess it won't be hard for you to "backup" your claims, but, let me give you a litle help:
...The continued enhancement of AMD and IBM's transistor strain techniques has enabled the continued scaling of transistor performance while overcoming industry-wide, geometry-related scaling issues associated with migrating to 45nm process technologies. In spite of the increased packing density of the 45nm generation transistors, IBM and AMD have demonstrated an 80 per cent increase in p-channel transistor drive current and a 24 per cent increase in n-channel transistor drive current compared to unstrained transistors. This achievement results in the highest CMOS performance reported to date in a 45nm process technology...
Source: HPCWire
“As the first microprocessor manufacturers to announce the use of immersion lithography and ultra-low-K interconnect dielectrics for the 45nm technology generation, AMD and IBM continue to blaze a trail of innovation in microprocessor process technology,” said Nick Kepler, vice president of logic technology development at AMD. “Immersion lithography will allow us to deliver enhanced microprocessor design definition and manufacturing consistency, further increasing our ability to deliver industry-leading, highly sophisticated products to our customers. Ultra-low-K interconnect dielectrics will further extend our industry-leading microprocessor performance-per-watt ratio for the benefit of all of our customers. This announcement is another proof of IBM and AMD’s successful research and development collaboration.”
Current process technology uses conventional lithography, which has significant limitations in defining microprocessor designs beyond the 65nm process technology generation. Immersion lithography uses a transparent liquid to fill the space between the projection lens of the step-and-repeat lithography system and the wafer that contains hundreds of microprocessors. This significant advance in lithography provides increased depth of focus and improved image fidelity that can improve chip-level performance and manufacturing efficiency. This immersion technique will give AMD and IBM manufacturing advantages over competitors that are not able to develop a production-class immersion lithography process for the introduction of 45nm microprocessors. For example, the performance of an SRAM cell shows improvements of approximately 15 per cent due to this enhanced process capability, without resorting to more costly double-exposure techniques.
Source: Physorg
This week IBM has tried to one-up Intel through openness. IBM is claiming a level of mastery around 32nm chips that rely on high-k metal gate technology. And IBM has announced plans to share that technology with all its chip friends, including foundry, memory and fabless companies.
Just to bring everyone up to speed, let's look at the 45nm situation.
Intel last month started cranking out processors made on a 45nm process that use the high-k metal gate technology. This makes Intel the first major chipmaker to replace the silicon used to insulate transistor gates with hafnium and a pair of still undisclosed metals. As a result, Intel can produce smaller, more energy-efficient products.
IBM won't start pumping out the hafnium-based parts until next year when its 45nm manufacturing process takes hold. At that point, only IBM and partner AMD will be able to take advantage.
Source: RegHardware
AMD and IBM have joined forces to make something Intel announced six months ago: high-k metal gate transistor technology for their jointly developed 45nm process.
Intel does have the edge with its Halfnium-Oxide based insulator whereas the AMD-IBM combo will continue to use strained silicon technology.
Their 45nm process is highlighted to have a lower current leakage and higher capacitance of transistors, for a lower power usage and improved performance.
Interestingly it's only planned for second generation 45nm and the first generation 32nm technology processes. Therefore, it seems like AMD's Shanghai core - its first 45nm core, coming next year - will still use traditional manufacturing technologies...
Source: Bit-Tech
The 10-metal-level process will use copper interconnects, porous low-k-dielectric films, embedded strained silicon and advanced annealing. It is unlikely that AMD will use metal gates and high-k dielectrics at 45nm, but it will deploy immersion lithography at that node for the first time.
AMD is collaborating on the 45nm technology with longtime partner IBM Corp. In 2005, the companies announced they would extend their joint process development work until 2011, covering the 32nm and 22nm process generations.
AMD claims to be closing the process gap with Intel. In December, AMD rolled out its first 65nm microprocessors and announced plans to introduce 45nm chips in mid-2008. "That will put us ahead of just about everyone," said Nick Kepler, VP of logic technology development at AMD...
For the critical layers at its 90nm and 65nm nodes, AMD has used dry 193nm lithography scanners from its main tool vendor, ASML Holding NV. But at 45nm, AMD will take the plunge into immersion scanners. The company will use ASML's TwinScan XT:1700Fi, a 193nm immersion tool with a numerical aperture of 1.2. That scanner will boost the depth of focus and provide a 40 percent gain in resolution, Kepler said...
At 45nm, AMD will use an IBM film that will have porous features and a k-value of 2.4. "Our films parallel the offerings from Applied Materials in k-value, but with better mechanical properties," said John Pellerin, director of logic technology development at AMD, adding that the films "do run on Applied's tooling."
Another key for AMD is to scale its embedded SiGe technology to the 45nm node. The strained SiGe technology is key in an effort to boost mobility, and reduce power consumption and leakage in next-generation designs.
Source: EETimes Asia
So, you still thinking AMD's 45nm process is inferior?
Ohh, wait a minute: why should I ask a stupid question to a stupid fanboy like you? :/
You're predictable. =)
I, on amdzone said:
"If H.264 encoding would be fully SIMD'ified then Core2 should be twice as fast as K8 per-clock per-core and guess what? It isn't twice as fast."
Scientia replied:
"Not for 64 bit SSE."
If this isn't proof enough that you have no idea what you are talking about then I'm not sure if I'm living on the same planet you are. There is no such thing as 64bit SSE in x86 ISA
If you take a program that uses SSE that was written years before Core2 and run it on Core2 those SSE functions will run at twice the rate they would on CPU with 64bit SSE ALUs. There is absolutely no need for any code change or recompile, you'll get the speedup no matter what.
The whole splitting of 128bit instructions into two 64bit ones is being done entirely in CPU microcode. There is no way a programmer could say "now please just run half of that 128bit SSE instruction". ISA simply doesn't allow it.
It is kind of funny I got banned from AMDzone simply for pointing out the obvious.
giant
"Unless, that is, Bulldozer has been pushed out to 32nm."
Exactly. K10 may be shrunk to 32nm first but with Bulldozer pushed back to 2010 I would expect it to start on 32nm.
Exactly. K10 may be shrunk to 32nm first but with Bulldozer pushed back to 2010 I would expect it to start on 32nm.
Well, this means that Bulldozer will be the first new uArch to take advantage of AMD/IBM's High-K process on the 32nm node.
I still have a question:
What will AMD do to counter Nehalem and derivatives?
Is Shanghai more than a "dumb shrink" as many fanboys tend to call it?
If AMD is going to release Bulldozer until the year 2010, this makes believe that they're confident in Shanghai's performance. :/
amd fan said....
I still have a question:
What will AMD do to counter Nehalem and derivatives?
Nothing. Nahalem will be Pentium 4 derivative: it will have very long pipeline and have high TDP. It has been recently reported that it will have TDP of 130 Fake-o-watts (~150W max).
LOL^2
Thanks for publishing all those press blurbs that confirm everything for me.
If IBM really had somethign so good they'd figure out a way to use it themselves vs. sell it to others.
What is so special about immersion; new equipment, new material, new yield loss modes, new process variation nodes. Its interesting that INTEL can produce similar dimesniosn with far cheaper dry lithography. You can't even figure out when an annoucment is actually a negative annoucment.
YOu talk a good story about architecture but when it comes to technology you are an idiot who doesn't know the first thing about process.
Care to share your qualifications and tell me how those press releases actual prove AMD/IBM have a proces that at all.
I was expecting this typical response from you. What else can you expect from a troll? =)
I'm still waiting for the links/source/proof/evidence/data that proves your point that AMD/IBM's process is inferior. LOL :)
Ohh, but wait. That's too much asking for a mentally challenged person like you... =)
Anyhow, arguing with you is like giving you credit for every crap you post, so I won't fall in this trap again. ;)
I'm still waiting for the links/source/proof/evidence/data that proves your point that AMD/IBM's process is inferior. LOL :)
The proof is right in front of you. Why do you suppose it is that a 2.6Ghz Phenom has a TDP of 140W when a comparable Intel Q6600 CPU has a TDP of 95W? This Xbitlabs article measures the power consumption and shows both fit within the stated TDPs.
(Link: http://xbitlabs.com/articles/cpu/display/amd-phenom.html)
All signs point to massive leakage issues with AMD's 65nm process. They can keep the leakage under control at low clockspeeds of 2.3GHz and below, but once it goes beyond that the TDP starts climbing and climbing 2.4Ghz is 125W, 2.6Ghz is 140W. What sort of power consumption do you suppose AMD will need to reach the promised 3GHz?
This will only get worse for AMD at 45nm: without the high-k metal gate the leakage just gets worse with each generation of process technology. AMD will enjoy the cost savings of moving to 45nm technology, but due to severe leakage issues, I doubt that they'll release much of a performance increase in terms of clockspeeds over 65nm. In fact, it's pretty likely that initial 45nm CPUs will clock lower than their 65nm parts - much in the same way AMD's dual core 90nm CPUs are faster than their 65nm dual core CPUs.
Giant:
I'm talking about 45nm. In no moment I mentioned 65nm.
Untill you and your troll friend can backup that nonsens about 45nm being an "inferior process" with TRUE evidence, then both of you are full of crap.
One last thig Giant: don't fall into Lex's level. :/
lex
"YOu talk a good story about architecture"
Yes, he talks with confidence and makes it sound as if he knows what he is talking about. Luckily for the most of the time he does but there have been cases where he has no idea what he is talking about. Just see his claims about 64bit SSE.
45nm is simple. AMD is suffering severe leakage issues at 65nm, and these just get worse at 45nm without the HK/MG technology. Intel was talking about a 10X reduction in gate leakage with it's 45nm process.
To be blunt: Depending on how stepping B3 of K10 works out, AMD will hit 2.8GHz, possibly 3GHz if they're lucky. Of course, 3GHz would be with a mammoth TDP. Their 45nm process will be about one speed bin behind their 65nm until they go HK/MG.
Giant,
The proof is right in front of you. Why do you suppose it is that a 2.6Ghz Phenom has a TDP of 140W when a comparable Intel Q6600 CPU has a TDP of 95W?
How funny Giant.
You actually give Erlindo the proof he was asking for.
You said many times here that the Pentium 4 was a bad processor design and that Intel actually had a very good 90nm process which the PentiumM showed; then why cant AMD actually has a good 65nm process with a “bad” design?
In what you base that Intel has a superior process and in what you base AMD has an inferior process?
Ho ho,
Just see his claims about 64bit SSE.
Then enlighten us all mighty one.
The last time I checked the SSE2/3 had 128 bit instructions!
Which had to be split in two 64 bit ones in order to be processed due to design limitation in Athlon (K8) Pentium4 and PentiumM.
You call Scientia stupid but the real stupid is you that keep saying there is no such thing has 128 bit SSE.
You guys are just nitpicking. SSE introduced 128 bit registers, but they were typically intended to be used for 4 32 bit operands. With SSE2 the range of operand sizes is pretty broad. I wouldn't call any of them particularly 64 bit or 128 bit or 32 bit, except perhaps the load/store instructions with those sizes. Go find something actually meaningful to argue about, please.
SSE (1,2,3) is a technology made work on 128bit blocks of data, just like MMX was but for 64bit chunks of data.
You can't say SSE2 "HAS" 128bit instructions, because that's silly, SSE has instructions that work on blocks of data smaller than 128bit, thats' true, but at foundations SSE is all about 128bit operations, that's the purpose of SSE. SSE works on 128bit from the first implementation, there is no such thing as 64bit SSE (other than the fact that the hardware used to break the SSE execution in 2 stages of 64 bit each)
Some people should at least have the most basic knowledge about what they are talking about before posting "http://en.wikipedia.org/wiki/Streaming_SIMD_Extensions"
SSE is 128bit and always was (this is not something that Core 2 brought, Core 2 brought 128bit execution per stage instead of 2 64 bit per stage, it removed the instruction breakup)
ho ho
"There is no such thing as 64bit SSE in x86 ISA"
Quite correct. I should have said 64 bit SIMD rather than SSE. AMD's 64 bit SIMD operations are of course MMX and 3DNow.
Where to do for the evidence of who has the best silicon?
Very simple
You can read all about INTEL, IBMs, and TSMC process at IEDM and VLSI conferences. The proceedings are for sale at IEEE.com and or you can go to the companies web site to see.
Pay special attention to the numbers each company claims for density: SRAM cell size, Gate, contact, and Metal 1 thru Metal 6 pitches. THat tells you how dense they can pack those tranisstors, and how well the can connect them up.
But since we aren't talking about making slow consumer electronic chips its also important how powerful those transistor are.
Pay special attention the the transistor drive current each company publishes and make sure you compare it at the same leakage. That tells you how much power you get, and for idiots like you its like how much HP for your MPG.
Happy googling and come back and tell me who is fastest, first and who might have the best ability to pack more transistors togather that result in cheaper and smaller chips that run fast and cool.
All the evidence is out there. Barcelona and Phenom clock speeds and power tell you how good AMD / IBM 65nm is against INTEL. We don't even need to start talking about quad core Penrym and Nehalem. How do you expect AMD/IBM to catch up if they can't even get 65nm working and competitive. Technology isn't something you can leapfrog like design/architecture.
Unfortunately for AMD Nehalem will pack more punch than most AMD (people/fans) predict. And there are some clues to this, the first one is that Intel will reintroduce hyper threading, which only makes sense when you can't keep the execution units fully occupied. Now if nehalem's execution units are not fully occupied considering the improved bandwidth adn latency of direct memory access and the fact that it's core 2 derived, this means that Intel has increased the pipeline width for nehalem compared to core 2 to 5 (maybe 6) simultaneous instructions, and they are taking advantage of the increased bandwidth. If this speculation is true, AMD is not prepared for nehalem and will once again take a heavy blow, and this time it might be fatal.
Blogger Pop Catalin Sever said...
Unfortunately for AMD Nehalem will pack more punch than most AMD (people/fans) predict. And there are some clues to this, the first one is that Intel will reintroduce hyper threading, which only makes sense when you can't keep the execution units fully occupied.
No. It makes sense when your execution units are stuck waiting for slow data accesses, like anything off-chip, because it allows another thread to attempt to make progress during those delays. It only helps when at least one of the two threads' data resides in L1/L2 cache. In a bandwidth-dependent workload it offers nothing. The fact that they're re-introducing hyperthreading is just an admission that they still haven't got enough memory bandwidth.
So no one here but me actually does assembly SSE code?
When one uses a term like "64-bit SSE," what they mean is that the code is written in such a way that it primarily works with 64-bit data blocks. The used instructions may be MOVSD, ADDSD, MULSD, etc, and are quite typically produced by all the standard compilers, as x87 isn't used for FP math anymore. Most compilers switched to *SD and similar instructions long ago.
All you people saying things like "there is no such thing as 64-bit SSE" are totally missing Scientia's point about performance differences between 128-bit and 64-bit SSE code/instructions. Further, it demonstrates that you really don't understand what's going on.
... I do: (I was slow to respond :))
It's fairly easy to trigger 64bit SSE; Most modern compilers will auto-switch to 64bit SSE once you start doing double precision math ("double").
Sample:
$ cat test.c
#include "stdio.h"
#include "stdlib.h"
int main(int argc, char *argv[])
{
double start, end;
const move = 2.3333;
start = 1.11;
end = start * move;
end += start;
printf("%f\n",end);
return 0;
}
$ gcc test.c -o test
$ objdump -S test | grep \<main\> -A27 | cut -f3
00000000004004b8 <main>:
push %rbp
mov %rsp,%rbp
sub $0x40,%rsp
mov %edi,-0x24(%rbp)
mov %rsi,-0x30(%rbp)
movl $0x2,-0x4(%rbp)
mov $0x3ff1c28f5c28f5c3,%rax
mov %rax,-0x18(%rbp)
cvtsi2sd -0x4(%rbp),%xmm0
mulsd -0x18(%rbp),%xmm0
movsd %xmm0,-0x10(%rbp)
movsd -0x10(%rbp),%xmm0
addsd -0x18(%rbp),%xmm0
movsd %xmm0,-0x10(%rbp)
mov -0x10(%rbp),%rax
mov %rax,-0x38(%rbp)
movsd -0x38(%rbp),%xmm0
mov $0x400618,%edi
mov $0x1,%eax
callq 4003b8 <printf@plt>
mov $0x0,%eax
leaveq
retq
nop
nop
nop
Spam said:
"All you people saying things like "there is no such thing as 64-bit SSE" are totally missing Scientia's point about performance differences between 128-bit and 64-bit SSE code/instructions. Further, it demonstrates that you really don't understand what's going on."
You got it wrong, SSE can work on 8, 16, 32 and 64 bit packed data, but that doesn't mean you can say SSE 8bit or SSE 16bit or SSE 64bit.
The packing of data (most comon, single precision 32bit or double precission 64bit) doesn't change the fact that SSE has 128bit wide registers and works different packed data. (With simple precision it can work on 4 data chunks in one pass with double precision it can work in 2 data chunks in one pass, that's why it is caled SIMD (Single instruction multiple data) but this doesn't change the fact that SIMD is 128bit, it has 128bit registers and works on 128 bit data packed as 16 bytes, or 8 words or 4 dwords or 2 qwords. SSE is 128 bit regardless of the paking of data it works on.
A clarifying read, very short and concise just 8 pages total:
http://www.intel.com/technology/magazine/computing/sw03011.pdf
Quote:
"
Intel SSE/SSE2 technology applies to elements of all standard data types, both floating-point (FP) and integer,
that fit into 16-byte-wide SSE/SSE2 registers
"
All data types that fit in 16 byte wide registers, 16 byte = 128 bit
You're wrong. Check Intel's
The upper 64bit of the target xmmN register remain -unchanged-. These are -not- a packed SSE instructions.
If you don't believe me, compile the code above and test it for yourself.
- Gilboa
Pop Catalin Sever,
SSE (1,2,3) is a technology made work on 128bit blocks of data, just like MMX was but for 64bit chunks of data.
You can't say SSE2 "HAS" 128bit instructions, because that's silly, SSE has instructions that work on blocks of data smaller than 128bit, thats' true, but at foundations SSE is all about 128bit operations, that's the purpose of SSE. SSE works on 128bit from the first implementation, there is no such thing as 64bit SSE (other than the fact that the hardware used to break the SSE execution in 2 stages of 64 bit each)
Some people should at least have the most basic knowledge about what they are talking about before posting "http://en.wikipedia.org/wiki/Streaming_SIMD_Extensions"
SSE is 128bit and always was (this is not something that Core 2 brought, Core 2 brought 128bit execution per stage instead of 2 64 bit per stage, it removed the instruction breakup)
Completely agree with you.
"You're wrong. Check Intel's
The upper 64bit of the target xmmN register remain -unchanged-. These are -not- a packed SSE instructions.
If you don't believe me, compile the code above and test it for yourself.
- Gilboa"
The upper 64bit is left unchanged because it uses the unpacked version of the operands (the scalar version) (SSE suports both packed and unpacked (scalar)operations) :)
SSE has unpacked versions for almost all operands even for 32bit, 16bit and 8 bit packing, but that still doesn't make SSE neither 64 nor 32 nor 16 bit instruction set, try doing 2 computations on 2 values at the same time and the compiler will replace the operands with packed version instead of the scalar version.
Well if you say that your code is writen in "SSE 64bit" then code using ADDSS or MULSS is writen in
"SSE 32bit"?
Comon, just bevause SSE has scalar instructions that operate on 64 bit or 32 bit or another doesn't make SSE 32bit or 64 bit....tha's the same SSE version that operates on diferent data sizes but is still 128 bit because that's the 'register size'
"Comon, just bevause SSE has scalar instructions that operate on 64 bit or 32 bit or another doesn't make SSE 32bit or 64 bit....tha's the same SSE version that operates on diferent data sizes but is still 128 bit because that's the 'register size'"
I'll make sort (I hate arguing about semantics).
addpd and addsd (E.g.) are different operands that are subject to different optimization.
Hence, the term "64bit SSE" is as valid as "32bit integer" or "single precision math".
- Gilboa
P.S. By posting a message here, you're essentially asking that we take the time to read your post. In return, please take the time to proof-read your messages before you post them.
There's no such term as 64 SSE, the term only came up on this blog. Didn't seen it anywhere else.
http://www.tommesani.com/SSE2MMX.html
And just to hammer the point the PHENOM BLACK EDITION is now available from Newegg.
aguia
"You call Scientia stupid but the real stupid is you that keep saying there is no such thing has 128 bit SSE."
Can you show us where did I say that? To make your life easier I'll say that I claimed the exact opposite.
scientia
"I should have said 64 bit SIMD rather than SSE. AMD's 64 bit SIMD operations are of course MMX and 3DNow."
Using MMX instead of SSE(1/2/..) is only useful if your target is older than P3 or Athlon. On pretty much anything newer you get better results with SSE. In short I doubt anyone uses MMX much nowadays. 3Dnow is even worse as it works on very small subset of CPUs.
spam
"All you people saying things like "there is no such thing as 64-bit SSE" are totally missing Scientia's point about performance differences between 128-bit and 64-bit SSE code/instructions."
Go see what Scientia himself said. This is not what he said or meant.
How does one gain access to
trackingamd.net?It says that one
needs an invitation to view the blog.
Now you can overclock your 2.3 to 2.4!
I have a friend that has one core at 3.2Ghz, two at 2.9Ghz and one at 2.7Ghz.
Not bad since most Q6600 buyers go from 2.4Ghz to 3.0Ghz with just a FSB change if the mobo is good.
He says its lighting fast, maybe not the benchmark winner but overall feels much faster than his previous E6600 @ 3.0Ghz. And since most applications he uses are mostly two cores it’s quite amazing/strange that he feels a difference between both systems.
mo,
Just to not let this one die, what do you really do for being all the day encoding and ripping?
Are you all the time in the video club pirating things to the net and share them through emule?
"Even though half of what I do on the computer is video/audio encoding/ripping which uses all 4 cores...."
Aguia,
apparently you don't get it either.
I'm glad your "friend" gets it though.
You yourself said that most of the programs he uses utilize dual cores, but yet he bought a quad core Phenom. You apparently don't have a problem with his quad-core AMD purchase, yet you have a problem with mine?
Double Standards much?
After seeing your "fair" approach on this matter, I don't feel the need to justify my computing behavior to you.
I'm sick and tired of the double standards you and few other AMD fanbois hold.
mo,
Don’t get me wrong.
I also don’t think he should have bought the AMD quad.
The reason he gave me was that his motherboard didn’t support Intel quad core CPUs.
So since he wanted to upgrade and think its "funny" the possibility to have 4 GPUs on his system so he has gone that AMD route.
And I don’t have double standards. I was only pointing to Hector de J. Ruiz, Ph.D that the OC is not only 100Mhz as his intended to say but at the same time not as good and easy as with the Q6600.
I would also go to Intel quad if I really wanted/needed a quad core CPU.
And of course you don’t have to say anything about what you do with your computer.
B3 (65nm) would be the last stepping.
The next is Cx (on 45nm)
I guess this means they are on track to deliver 45nm.
http://www.theinquirer.net/gb/inquirer/news/2008/01/11/barcelona-b3s-fine
one more interesting thing they were able to test the bug fix on B2 silicon. If they would be able to do that last year with the Barcelona it may not be delayed that much.
AMD 45nm comes in 2009 according to Phil Hester:
He also said that AMD is on schedule to come out with its 45-nanometer manufacturing process in 2009 as well.
http://www.mercextra.com/blogs/takahashi/2008/01/08/ces-live-deans-tuesday-experiencemeeting-with-amds-phil-hester/
This means Nehalem will arrive before Shanghai.
Kedas wrote: B3 (65nm) would be the last stepping.
The next is Cx (on 45nm)
I guess this means they are on track to deliver 45nm.
http://www.theinquirer.net/gb/inquirer/news/2008/01/11/barcelona-b3s-fine
one more interesting thing they were able to test the bug fix on B2 silicon. If they would be able to do that last year with the Barcelona it may not be delayed that much.
I have the feeling that AMD is trying as hard as possible to shift away their quad offerings from the 65nm process. Stepping Cx should bring great benefits to AMD and there are rumors that the second iteration of the 45nm process will include High-K.
Who knows,maybe 45nm on the third quarter, and High-K 45nm on 2009. This is a "do-or-die" situation.
AMD talks about closing the gap in process technology between themselves and Intel, but in fact the exact opposite is true. Intel released 65nm products in late 2005. AMD did so one year later, in late 2006. That's a difference of one year.
Intel released 45nm products in November 2007. AMD won't launch 45nm products until 2009, according to the AMD CTO. That's a difference of at least 14 months. It gets even worse when you consider that AMD's initial 45nm process won't use the HK/MG technology.
Stepping Cx should bring great benefits to AMD
1) Reduced die size
2) Larger L3 cache
3) Minor tweaks to the architecture
This is basically the same that Intel got when going 45nm. This should boost performance on average 5 -> 10% at the same frequency.
The disadvantage for AMD will be that 45nm CPUs will almost certainly launch at lower clockspeeds than the existing 65nm. This is exactly the same as when AMD went from 130nm -> 90nm and from 90nm -> 65nm.
Giant,
It’s already 14-01-2008 and tell me what 45nm CPU besides Core 2 Extreme QX9650 Intel is selling?
At $1075 each it’s more like selling ES to the general public don’t you think?
In fact Intel can even come to the press and claim its manufacturing 45nm CPUs in volume to meet demand (the QX9650), and that volume is two or three guys that want one of those.
Reality check Intel paper lunched 45nm CPUs in November 2007.
aguia
"It’s already 14-01-2008 and tell me what 45nm CPU besides Core 2 Extreme QX9650 Intel is selling?"
I see 11 45nm CPUs listed (9 when not counting combos) versus three AMD quads.
"Reality check Intel paper lunched 45nm CPUs in November 2007."
Reality check: intel released bunch of Xeons and one desktop CPU in November and I can see many Xeons on sale in retail in Newegg. AMD "launched" Barcelona in September and there are zero availiable from Newegg more than four months later.
In what kind of reality do you live in? It seems to be vastly different from the one I'm in.
Didn't someone define that processor launch is not paperlaunch if you can buy it from Newegg month later?
Whoops, make that two AMD quads instead of three.
The QX6950 is the obvious 45nm CPU. You can already buy 45nm Xeon servers and workstations from Dell, HP etc.
By the end of the month the dual core 45nm CPUs will be here (you can already buy them in some places) in both desktop and notebooks.
This is in contrast to AMD who launched Barcelona more than four months ago - and you still can't buy a server with these CPUs in it.
Ho ho
I see 11 45nm CPUs listed (9 when not counting combos) versus three AMD quads.
Thanks ho ho, but you need to go and get your eyes check, because I see too much Intel pro fan boy talk and AMD pro fan boy talk ;)
From Intel:
There are 11 cpu listed but only 5 can be bought.
Out of those 5 only 2 are desktop CPU.
Out of the desktop none are volume processors, unless you think $1075 cheap prices...
From AMD:
Where you can see 3 cpu listed I can’t see none. None of those CPUs are 45nm parts. Only a fanatic AMD fan boy can see 3 45 nm CPUs listed there.
Giant,
The QX6950 is the obvious 45nm CPU. You can already buy 45nm Xeon servers and workstations from Dell, HP etc.~
But the important ones: Core 2 duo E8200 or the Core 2 duo E8400 from the duals, and from the quad the Core 2 quad Q9300 and the Core 2 quad Q9450 where are they?
Those would be 45nm CPUs that “everyone” could buy.
The others are just paper launch. And the server I bet some are also just for show.
I remember when I wanted to buy Servers with the Xeon 31xx and the OEM wanted to force me to buy the Xeon 30xx. I even asked them if the 31xx where just show off. I did still bought the 31xx but with a 3 months delay.
Hey Aguia:
Don't feed the trolls!! =)
Don't feed the trolls!! =)
Oh yes, we're trolls for telling the truth. Intel is shipping plenty of 45nm CPUs now and has two more 45nm fabs coming online this year to meet demand.
Pop Catalin Sever
"Unfortunately for AMD Nehalem will pack more punch than most AMD (people/fans) predict."
Yes and no. In terms of desktop applications and single threading, doubtful. In terms of server applications, more likely.
"And there are some clues to this, the first one is that Intel will reintroduce hyper threading, which only makes sense when you can't keep the execution units fully occupied."
This assumption is faulty. The fact that Intel needs hyperthreading does not prove or even indicate that Nehalem has higher IPC. We have a full spectrum of multi-threading from DEC's excellent EV-8 to Intel's poor P4. EV-8 has excellent IPC with all threads but much lower with only one. P4 however had poor IPC regardless.
"Now if nehalem's execution units are not fully occupied considering the improved bandwidth adn latency of direct memory access"
EV-8 also used an IMC but as I mentioned did not have good IPC for single threads.
"and the fact that it's core 2 derived,"
I think this is a leap of faith on your part. The indications are that Nehalem is quite different from C2D.
" this means that Intel has increased the pipeline width for nehalem compared to core 2 to 5 (maybe 6) simultaneous instructions, and they are taking advantage of the increased bandwidth."
Again, I've seen nothing that would indicate this. We currently have almost no information on Nehalem's architecture.
" If this speculation is true, AMD is not prepared for nehalem and will once again take a heavy blow, and this time it might be fatal."
I think you will find that Nehalem is a better server processor and worse desktop processor than Penryn.
Scientia
I think you will find that Nehalem is a better server processor and worse desktop processor than Penryn.
Please explain why you feel that Penryn will be a better Desktop processor than Nehalem.
The only thing that I have seen is an article from HKEPC, which is claiming a 10-25% improvement on single threaded performance.
giant
The reason AMD was behind in 65nm was FAB 36. FAB 30 was never capable of producing 65nm chips. AMD did not want to buy new tooling for FAB 30 to make it 65nm capable because FAB 30 used 200mm wafers and any new tooling would have been obsolete at purchase.
So, AMD had to wait on FAB 36. Once FAB 36 was up, everything progressed normally. In Q1 AMD did 90nm testing, in Q2 they did 65nm testing, in Q2 they began 65nm production and these were delivered in Q4. I don't see any way that this could have been speeded up.
When we talk about 45nm, however, things are completely different. There has been no delay waiting for a FAB to get built. The initial tooling for 45nm was installed in FAB 36 which was already 300mm and had been fully converted to 65nm.
If we apply the demonstrated timeline for 65nm once FAB 36 was available to 45nm we would still have 45nm parts coming out in Q3 2008.
Yes, I know you enjoy pouncing on the 2009 date but that almost certainly refers to 45nm conversion rather than the start of production. FAB 38 will be 45nm at startup and FAB 36 should be delivering test samples of 45nm processors in this quarter.
Intel's 45nm production has been worse than they expected; that is truth. However, it will improve. Intel should have a good volume of 45nm chips in Q2 with clocks of at least 3.16Ghz. From what we can tell, AMD will still only be at 2.6Ghz in Q2.
enumae
That is possible but that information is not coming from intel. If Nehalem has something to brag about I'm sure Intel will start making it known in Q2.
I have a lot of doubt about Nehalem's performance because it will almost certainly have a longer pipeline than C2D. It seems to include a lot of design from the original Nehalem which was derived from P4.
"This assumption is faulty. The fact that Intel needs hyperthreading does not prove or even indicate that Nehalem has higher IPC"
I doesnt' mean it has higher IPC per thread, the fact that nehalem needs hyperthreading means that it has more execution units or the fact that its execution units are starved, in both cases the hyperthreading will lead to more "overall IPC" if such term exists.
Also nehalem is core2 derived and core2 shows little scaling with increased bandwidth 1333 to 1600 FSB, which means Core 2 is IPC limited and increased bandwidth doesn't help anymore (with few exceptions ofcourse), on the other hand nehalem has more bandwidth to feed the pipeline and lower memory latency but Intel still thinks the execution units are not fully utilized and therefore they are introducing hyperthreading, all of this leads to the conclusion that nehalem has more execution units than Core 2.
Yes, single threaded applications won't benefit much from a wider pipeline because the limit of how many instructions can be executed in parallel has pretty much been reached by Core 2 (only marginal improvements from here).
P.S. Core 2 might also be latency limited but is of much smaller effect than IPC limitations and all tests using various cache sizes from 2 to 4 to 6 (Penryn) seem to show this) Also if it were latency limited there would have been very bad scaling with frequency which is not the case.
I noticed a typo in my reply to giant. It should say that 65nm testing was in Q2, production, in Q3, and delivery in Q4.
Pop Catalin Sever
"I doesnt' mean it has higher IPC per thread, the fact that nehalem needs hyperthreading means that it has more execution units or the fact that its execution units are starved, in both cases the hyperthreading will lead to more "overall IPC" if such term exists."
Again, we don't know the nature of this. EV-8 had massive decoding capability and was able to decode multiple threads per core without delay. This allowed the extra threads to fill in gaps in the pipeline that would have been caused by data dependencies or branches.
Pipeline stalls on Northwood were bad and very bad on Prescott with its 31 stage pipeline. Unfortunately, with its decoding ability, this architecture had to rely on the trace cache. This design is completely the opposite of EV-8.
"Also nehalem is core2 derived and core2 shows little scaling with increased bandwidth 1333 to 1600 FSB, which means Core 2 is IPC limited and increased bandwidth doesn't help anymore (with few exceptions ofcourse),"
Your description is too simple. For benchmarks that fit inside the L2 cache you won't see any benefit. However, it is clear that Penryn is not IPC limited when running 4 different threads.
" on the other hand nehalem has more bandwidth to feed the pipeline and lower memory latency"
Nehalem does indeed have more bandwidth with 4 cores. But, with DDR3 FBDIMM I don't think we will see any real reduction in latency.
" but Intel still thinks the execution units are not fully utilized and therefore they are introducing hyperthreading, all of this leads to the conclusion that nehalem has more execution units than Core 2."
Or that Nehalem suffers from a longer pipeline and is more sensitive to missed branches. Or that Nehalem has better decoding than Penryn or that Intel feels that the decoding capacity of Penryn is not saturated. Assuming more execution units is premature.
"Yes, single threaded applications won't benefit much from a wider pipeline because the limit of how many instructions can be executed in parallel has pretty much been reached by Core 2 (only marginal improvements from here)."
I wouldn't say that. C2D can still be improved in several ways. Again, your assumption of a wider pipeline is a bit hasty.
"P.S. Core 2 might also be latency limited but is of much smaller effect than IPC limitations and all tests using various cache sizes from 2 to 4 to 6 (Penryn) seem to show this) Also if it were latency limited there would have been very bad scaling with frequency which is not the case."
Latency is a factor when you have code with lots of branches. Frequent branches that are hard to predict will cause cache misses and this is where latency comes in. This does not cause any general limitation in scaling.
"Again, we don't know the nature of this. EV-8 had massive decoding capability and was able to decode multiple threads per core without delay. This allowed the extra threads to fill in gaps in the pipeline that would have been caused by data dependencies or branches."
Yes, this is exactly the reason why nehalem will have hyperthreading, to fill the pipeline gaps caused by the times when not enough instructions can be processed in parallel, but Penryn alreay has a high IPC considering the number of instructions it can process in parallel. Penryn can theoretically process 5 instructions (with macro fusion) and 4 without, but the actual average IPC of Penryn can be as high as 3 instructions per clock (even higher for certain applications), which doesn't leave much space in the pipeline to run a parallel thread, so therefore hyperthreading for nehalem (wich is Penryn based not P4 based, Intel scraped P4 arch and recycled the name but for different project than the nehalem planed in 2000) only makes sense if the pipeline is wider than the pipeline for Penryn.
"Pipeline stalls on Northwood were bad and very bad on Prescott with its 31 stage pipeline. Unfortunately, with its decoding ability, this architecture had to rely on the trace cache. This design is completely the opposite of EV-8."
There are many areas that Intel improved for Core 2 to reduce pipeline stals besides shorter pipeline. Core 2 is not plagued by the same problems of Netburst (most of which were because of the pipeline length indeed)
"Your description is too simple. For benchmarks that fit inside the L2 cache you won't see any benefit. However, it is clear that Penryn is not IPC limited when running 4 different threads."
There are few benchmarks that fit in cache, they are called microbenchmarks and I wasn't talking about them. SuperPI is supposedly one of such benchmarks, but I never take artificial benchmarks into consideration just the application benchmarks.
"Nehalem does indeed have more bandwidth with 4 cores. But, with DDR3 FBDIMM I don't think we will see any real reduction in latency."
Nehalem has quadchannel FB-DIMM memory support which will reduce latency substantially, it can also operate using DDR3 memory, so the latency will be smaller, first of all because of the lack northbrige and fsb. Intel server processors now use FB-DIMM through northbridge and FSB(single or dual), so a direct connect architecture that eliminates the northbridge and also at least doubles the number or channels will decrease latency, because more dims can be accessed directly and the intermediate point (northbridge) is eliminated.
"Or that Nehalem suffers from a longer pipeline and is more sensitive to missed branches. Or that Nehalem has better decoding than Penryn or that Intel feels that the decoding capacity of Penryn is not saturated. Assuming more execution units is premature."
Don't think it suffers from a significantly longer pipeline, because like I said is Penryn based. Also decoding isn't and never was an issue for any type of processor, decoding is one type of bottleneck that can be eliminated by simply adding more decoders, and I'm sure that having 4 decoders for a core than issues 3 instructions per clock is more than enough (if not intel can add more decoders simple or complex as they see fit until this is not a bottleneck, which is a much better (and maybe simpler) solution to increasing IPC than hyperthreading). I'm positive that Penryn is not decoder limited there's not a single thing that can show that.
"I wouldn't say that. C2D can still be improved in several ways. Again, your assumption of a wider pipeline is a bit hasty."
Yes it can be improved, but statistical analysis shows that there is a limited amount of parallelism that can be extracted from x86 code. One way to improve Core 2 would be to reduce various instruction latencies.
"Latency is a factor when you have code with lots of branches. Frequent branches that are hard to predict will cause cache misses and this is where latency comes in. This does not cause any general limitation in scaling."
No not really, bad data locality cause cache misses and not necessarily branches, you can have branchy code with good data locality that doesn't cause cache misses and the opposite is also true you can have linear code with bad data locality that causes lots of cache mises.
Branch prediction is not necessarily hard to do if there are allot of branches, but the type of those branches and instruction usage makes it hard or easy to predict them.
Pop Catalin Sever
"but Penryn alreay has a high IPC considering the number of instructions it can process in parallel. Penryn can theoretically process 5 instructions (with macro fusion) and 4 without, but the actual average IPC of Penryn can be as high as 3 instructions per clock (even higher for certain applications)"
The actual typical IPC is less than 2.5. To properly handle a second thread Nehalem would have to double Penryn's decoding resources. This is possible but it is no small investment in chip real estate. Each thread would need its own branch tables, cache resources, prefectch resources, etc. Given the existing Penryn pipeline, a better balance would probably be a second complex decoder and a fourth simple decoder. This should be enough to keep the pipeline nearly full. You seem to be theorizing that Nehalem actually has more execution units and a wider pipeline. This again is possible but unlikely. The additional chip area required would be out of proportion with the gain in speed. In other words, it would be economical to simply add another core.
" nehalem (wich is Penryn based not P4 based, Intel scraped P4 arch and recycled the name but for different project than the nehalem planed in 2000) "
No. Tejas was orignally due in 2005 and Nehalem due in 2007. Tejas was scrapped but the work done on this was released as Tulsa in 2006. Whitefield was supposed to arrive in 2007 to fill in for Nehalem's delay and lay the foundation for CSI. This was scrapped so Intel came up with Tigerton. The original work on Nehalem was overhauled with input from the C2D project and this pushed Nehalem back by a year to 2008. We should see substantial differences between Nehalem and Penryn architecture when these details are released which show that Nehalem is not a C2D derivative.
"There are many areas that Intel improved for Core 2 to reduce pipeline stals besides shorter pipeline. Core 2 is not plagued by the same problems of Netburst (most of which were because of the pipeline length indeed)"
C2D has dedicated stack hardware and substantially expanded prefetchers. The L2 cache is much larger. The decoding bandwidth is higher. And, the pipeline is shorter. All of these things help. However, there is no doubt that lengthening the pipeline substantially will hurt. I would not be surprised if Nehalem's pipeline is as long as Northwood's 20 stages.
"Nehalem has quadchannel FB-DIMM memory support which will reduce latency substantially, it can also operate using DDR3 memory, so the latency will be smaller, first of all because of the lack northbrige and fsb."
Not really. More channels increases the total bandwidth. However, the lack of a FSB means that the access optimizing and prioritization functions have to be moved to the processor die. This again is not a minor increase in chip real estate. The lack of a FSB will help but FB-DIMMs daisy chain linkage insures latency whenever more than one DIMM per channel is used.
Nehalem is Penryn based
http://www.pcper.com/article.php?aid=382&type=expert
http://www.intel.com/pressroom/archive/releases/Intel_New_Processor_Generations.pdf
"Leverages leading 4 instruction issue Intel® Core microarchitecture technology"
Nehalem also supports SSE 4.2 which is a superset of Penryn's SSE 4.1 ( http://en.wikipedia.org/wiki/SSE4 )
It also uses Penryn's fabrication process brought to the second generation.
The Nehalem core might not be a direct successor of penryn from all points of view, but nonetheless it's core 2 derived and includes some of the enchantments Penryn brought and also is build on the next generation fabrication process that Penryn is built with.
Intel scraped Netburst in all of its roadmaps, the last processor to using netburst was Presler.
I know that the initial roadmap for Nehalem was :
Prescot->Thejas->Nehalem
but after scraping Netburst the roadmap for Nehalem is :
Kentsfield->Yorkfield->Nehalem
In regards to your Deja vu article on AMDZone.....
How about AMD Demoing 3ghz but we won't see that..............seemingly ever. Remember your Q1 estimate that got shifted to Q2 and where do we stand on 3ghz phenoms Mr. Sci?
Lack of competition halts advancement. Both Intel and AMD are guilty of this. (AMD MILKED the k8 because Intel had no competition). Intel straight out said that penryn is delayed due to the lack of competition from AMD.
It's common sense that a company will mill their cash cow for as long as they can.
If Intel is producing lower bin chips at a lower cost (higher yield), and it's still edging out the competition, why in the world would they need high binned (lower yield) chips?
Have AMD push out a 3ghz chip and then we will see where Intel stands.
Mo,
Intel has issues. Period.
http://www.dailytech.com/article.aspx?newsid=10362
About your demo 3.0Ghz CPU not yet available is much in line with what I previous said about Intel too, remember the Intel 3.33Ghz quad or dual show off years ago that we don’t have seen yet?
Well it seems AMD likes to copy Intel bad moves. And Intel likes to copy AMD bad moves. Funny isn’t it?
PS: And MO since it has passed a lot of time and you didn’t reply to my question of what you do with your quad core CPU. I assume that you agree with me and all the others that said quad core CPUs is over kill and not needed unless you like to run sisoft and other useless performance simulation benchmarks.
Aguia, I don't own a quad-core but I was speaking hypothetically.
Even if I used a multi-threaded software 25% of the time, it's still a good justification to buy a quad-core.
With Quad-Core pricing these days, why the heck not?
I would like to save time that 25% of the time, and a quad core would allow me to do that.
As far as what I do with my computer, I already told you that I'm not going to explain my computing behavior.
The 3Ghz remark was strictly towards Sci because he attacked us when we said that 3Ghz won't happen till late Q2 and maybe even later in the Year.
He insisted that it takes 6 months for AMD to put out a demoed chip... and now, 3ghz Is no where on AMD's roadmark, let alone a 2.6ghz chip.
mo,
Yes mo, but the point is quad core or (even more) with servers very good, desktop except encoding I can't find real reasons to go after it.
The price while cheap, it is not so today because for example here in my country I can buy 8GB DDR2 800Mhz for "just" 130€. What I want to mean with this is that PC components prices today dropped so much that even just 200€ looks expensive. The cheapest dual cost around 60€ the cheapest quad around 200€. It’s still a good difference and to just benefit from it (right now) in encoding applications seems little.
For example my PentiumM 1.86Ghz when encoding with DVDshrink sits around 600Mhz/800Mhz while encoding thanks to speedstep, and why, the DVDROM simply can’t read the data fast enough so the processor has to wait for it to be processed, so I assume that having a dual wouldn’t help either.
Yes scientia is wrong for the same reason ho ho (I think) was wrong (1 year ago) where he claimed Intel could release a 3.0Ghz quad while I said no because that would have to be with a TDP of 160W (or more) if Intel did so.
Besides Scientia only said that because AMD “never” have done that before (I think), however at Intel is common practice.
Mo
How about AMD Demoing 3ghz but we won't see that .............. seemingly ever.
I've already mentioned how that demo was smoke and mirrors. A proper release date would be six months later. Yet, we apparently aren't going to see it even 9 months later in Q2. So, either AMD won't hit 3.0Ghz on 65nm until a full year after the demo or they have scrapped further 65nm development in favor of 45nm.
"(AMD MILKED the k8 because Intel had no competition)."
Not true at all. There is every indication that all of AMD's design capacity was full from 2002 until today.
" Intel straight out said that penryn is delayed due to the lack of competition from AMD."
Yes, and I'm sure the second FAB delay and the low yields were also caused by this. The fact is that Intel has had some difficulty with 45nm however it has hurt because of the lack of competition. In short, Intel is bending the truth.
"why in the world would they need high binned (lower yield) chips?"
It's not a question of what they need; it's a question of what they have. If they had the chips they would sell them. The lack of competition has no effect on Intel's yields or bins.
You can try this ridiculous tap dance to explain Intel's delays but the truth is that Intel would be perfectly happy to see AMD's midrange fall into Celeron territory. Again, Intel's delays are caused by technical difficulties rather than choice. However, the delays don't really matter at this point because AMD's delays are larger.
Pop Catalin Sever
"Leverages leading 4 instruction issue Intel® Core microarchitecture technology"
That's a non-technical press release. Let's see what the technical details actually are. If Nehalem's architecture is similar to Penryn's then you'll be right.
mo
"The 3Ghz remark was strictly towards Sci because he attacked us when we said that 3Ghz won't happen till late Q2 and maybe even later in the Year."
LOL. Attacked? Really? See if you can spin a little harder. The actual word, Mo, is "disagreed".
"He insisted that it takes 6 months for AMD to put out a demoed chip... and now, 3ghz Is no where on AMD's roadmark, let alone a 2.6ghz chip."
No. What I gave was the normal estimate for a demo chip to appear. Intel had very similar demos and deliveries with C2D in 2006. Since AMD is not meeting this schedule we have to conclude that the demo was not honest.
Scientia, in the AMD conference call they said that Puma had over 100 design wins. This sounds like good news. Do you know anything about the Puma design and how it is progressing?
It also looks like AMD might be out of the woods as far as going bankrupt anytime soon. 9 million non-gaap loss looks pretty good.
AMD also said it will be shipping samples to customers of B3 in a couple weeks with production showing up in platforms towards the end of the quarter.
400,000 Quade Cores Shipped!
AMD did alot better this time. Things should get even more better in the upcoming quarters with the release of stepping B3, better performing Radeons and Shanghai.
Upbeat AMD Report Pleases Investors
Post a Comment